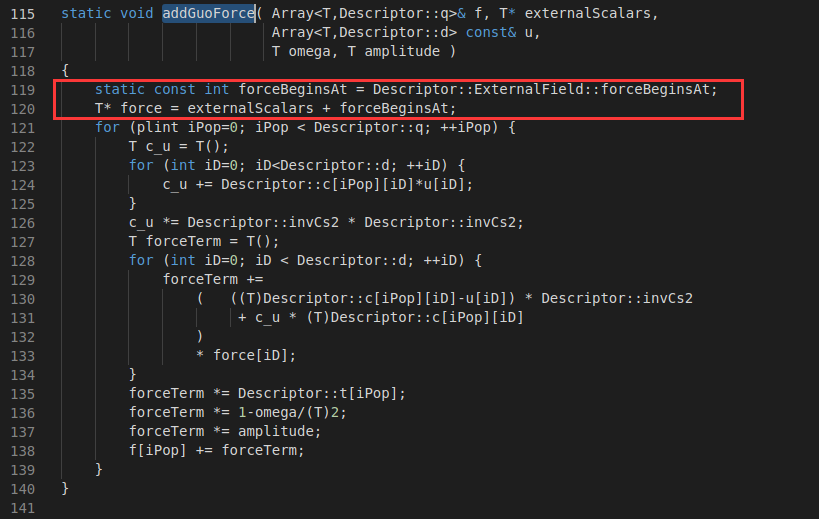
Hello, everyone! I am new in Palabos, I want to know what is the relationship between “forceBeginsAt” and “externalScalars”. Why is “forceBeginsAt + externalScalars” applied to “addGuoForce”(externalForceTemplates<T,Descriptor>::addGuoForce) but “forceBeginsAt” is applied to “ShanChenExternalForceBGKdynamics” (externalForceDynamics.hh). It’s been bothering me for a long time, looking forward to your reply!

Hello gyl!
This is just how arrays work in C++. For example for
int a[4] = [0, 1, 2, 3];
a points to the first element in the array, and in general a+i to the (a+i)-th, for all i in range. Accessing an array with brackets is therefore equivalent to dereferencing the pointer to get the value, meaning a[i] is equivalent to *(a+i). In this example, if we create the pointer
int* b = a+2;
we will have a pointer to the memory address of third integer in a (=2). We can dereference it with *b to get the 2 and *(b+1) to get 3. But since the brackets are equivalent, we can also use b[0] and b[1] to get the same values.
Using this, it is possible store all the external scalars of the lattice in just one array, making sure they are next to each other in memory (which makes for faster access). By saving the index shifts in integer variables, like forceBeginsAt, we have a very convenient way to access the values – without memorizing their positions in each lattice.
The Palabos function getExternals() just calls get(), which returns data+index (you can look it up to find out what exactly data is), so, under the hood, it does basically the same as we discussed above. It is just more convenient for the user and the function makes sure that an error is thrown if you use an index that is out of range.
Hi, bkellers
Thank you very much for your patience to answer my question. It was very helpful!
Best wishes,
gyl